5. Описание программного
обеспечение для построения деревьев решений.
В настоящее время, известны
несколько десятков компьютерных программ для построения деревьев решений. Эти
программы отличаются кругом решаемых задач, используемыми методами, уровнем сервиса,
предоставляемого пользователям. Многие программы имеются в сетях Интернет в
свободном или ограниченном доступе (позволяющем познакомиться c программой).
Одними из самых популярных в мире сейчас являются программные системы CART
(предназначенная для решения задач распознавания образов и регрессионного
анализа), а также система С4.5 (для решения задач распознавания).
Для самостоятельного
изучения, можно обратиться к интернет-сайту http://www.recursive-partitioning.com/,
в котором содержится большая справочная информация, ссылки на
интернет-страницы, где описаны различные алгоритмы и программы для построения
деревьев решений (на английском языке), а также другие материалы. С широко известной программной системой CART,
предназначенной для построения деревьев решений в задачах распознавания образов
и регрессионного анализа, можно
познакомиться на сайте http://www.salford-systems.com/.
В Институте математики СО РАН разработана система ЛАСТАН, предназначенная для решения задач распознавания и регрессионного анализа. В настоящее время, ведется работа над новым вариантом, позволяющим также решать задачи кластерного анализа и анализа временных рядов. Система работает в операционной среде WINDOWS.
В системе ЛАСТАН реализован рекурсивный метод построения дерева решений (параметр α (параметр соотношения сложности и точности), для простоты, выбран равным единице). В данной версии используются также следующие ограничения:
максимальное число объектов – 200,
максимальное число переменных – 20,
максимальное число классов –10.
Чтобы провести анализ таблицы данных, после запуска программы необходимо проделать следующие шаги:
1.Открыть Ваш файл (File|Open). Если такого файла еще нет, выберите File|New (для удобства, можно пользоваться соответствующими пиктограммами).
Данный файл должен быть текстовым и записан в следующем формате, например:
(текст между символами # # является комментарием и игнорируется программой).
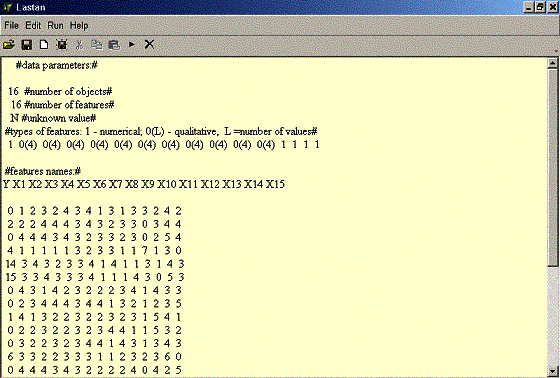
16 #задается число объектов #
16 #число переменных #
N #обозначение пропуска (неизвестного значения)#
#вектор типов переменных: 1 - количественная; 0(M) – качественная, где M =число значений #
1 0(4) 0(4) 0(4) 0(4) 0(4) 0(4) 0(4) 0(4) 0(4) 0(4) 0(4) 1 1 1 1
#названия переменных: #
Y X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13 X14 X15
#таблица данных; числа должны быть отделены пробелом или запятой; десятичные
значения отделяются точкой#
0 1 2 3 2 4 3 4 1 3 1 3 3 2 4 2
2 2 2 4 4 4 3 4 3 2 3 3 0 3 4 4
0 4 4 4 3 4 3 2 3 3 2 3 0 2 5 4
4 1 1 1 1 1 3 2 3 3 1 1 7 1 3 0
14 3 4 3 2 3 3 4 1 4 1 1 3 1 4 3
15 3 3 4 3 3 3 4 1 1 1 4 3 0 5 3
…………………………………………
Вы можете редактировать этот файл, используя встроенный редактор.
Имеется также возможность, используя построенное
дерево решений, найти прогноз для новых
наблюдений. Для этого нужно, после вышеупомянутой таблицы данных, написать
ключевое слово Predict, указать число объектов для прогнозирования, затем
должна следовать таблица с данными для прогнозирования (в которой, вместо
значений прогнозируемой переменной ДОЛЖНЫ быть указаны символы неизвестного
значения). Например:
predict 20
N 4 1
4 3 4 3 3
3 1 1 1 4 0 4 3
N 4 3
4 3 3 3 1
1 1 4 3 3
0 5 3
N 1 1
1 1 1 3 2
3 3 1 1 7
1 3 0
N 3
4 3 2 3 3
4 1 4 1 1
3 1 4 3
N 1
4 2 4 2 3
4 3 1 4 1 3 2
2 4
…………………………………………
2. Задать параметры алгоритма(Run|Parameters)

Описание параметров:
Ø Recursive complexity (рекурсивная сложность):
задает количество признаков, входящих в сочетание, рассматриваемое в ходе
работы программы (глубину перебора). При увеличении этого параметра
увеличивается как качество решения, так и время счета и требуемая память.
Целая часть параметра задает гарантированный размер (r) сочетания признаков.
Дробная часть параметра задает долю самых информативных признаков
(для которых ожидаемая ошибка наименьшая), отбираемых для перебора
сочетаний размера r+1, r+2 и т. д. (из признаков, выбранных на предыдущем этапе).
Ø Homogeneity (параметр однородности):
Вершина не подлежит дальнейшему ветвлению, если объекты, ей соответствующие,
являются однородными. Однородными считаются объекты, для которых
относительная дисперсия прогнозируемой переменной (либо относительная ошибка
распознавания, в случае прогнозирования качественной переменной) меньше
заданного параметра.
Ø MinObjInNode (минимальное число объектов в вершине; относительно их общего числа):
задает минимальное допустимое число объектов в вершине, подлежащей дальнейшему
ветвлению (т.е. если в вершине остается объектов не больше, чем указано, то из этой вершины ветвление далее не производится).
Ø VariantsNumber: желаемое число вариантов дерева. Варианты строятся путем последовательного исключения наиболее информативной переменной (соответствующей корню дерева) в предыдущем варианте.
Ø FeatureToPredict: номер прогнозируемой переменной;
Ø FoldsCrossValidate:
Параметр L в методе L-кратной перекрестной проверки. При использовании этого метода исходная выборка случайным образом делится на L частей, приблизительно одинаковых по объему. Затем каждая часть поочередно выступает как контрольная выборка, а оставшиеся части объединяются в обучающую. Показателем качества метода служит усредненная по контрольным выборкам ошибка. В случае задачи регрессионного анализа, ошибка (среднеквадратичное отклонение) нормируется к исходному значению.
3. Запустить программу построения дерева (Run|Grow Tree)
4. Результаты автоматически сохраняются в файле 'output.txt' . Для каждого варианта дерева приводится ошибка перекрестной проверки.